



 SpikeFun - Artificial Nervous System Demo
SpikeFun - Artificial Nervous System DemoSpikeFun je u stvarni front-end za "DigiCortex" biblioteku koja je engine za simulaciju unutra i koju polako razvijam kao hobi u slobodno vreme.
Sta se simulira
DigiCortex modelira neurone do nivoa sinaptickih receptora uz pomoc Izhikevich-evog neurona i/ili Brette-Gerstner / "AdEx" modela neurona. Izhikevich-ev i AdEx modeli su fenomenoloski, za razliku od, recimo, Hodgkin Huxley modela sto znaci da su dizajnirani da reprodukuju ponasanje neurona a ne detaljno svaku od jonskih struja, ali su i pored toga u stanju da vrlo verno repliciraju ponasanje 20 vrsta kortikalnih neurona uz drasticno smanjenu kompleksnost u odnosu na Hodgin Huxley model. Izhikevich-evi i Brette-Gerstnerovi modeli su, zapravo, najbolji odnos izmedju bioloske realnosti i kompleksnosti ako se simulacija radi na nivou akcionih potencijala (spajkova).
Moja implementacija je trenutno optimizovana za Intel platformu, ukljucujuci i Sandy Bridge (AVX), mada mi je glavni cilj da implementiram simulaciju na GPU platformama (CUDA, OpenCL) posto je update provodljivosti receptora posao kao stvoren za graficke procesore. Vec je uradjen task-manager koji uposljava worker niti, i koji ce vam lepo zakucati procesor na 99-100% bez obzira na broj jezgara (limit je 256 za sada :-)
Neuroni su modelirani kao vise-kompartmentalni modeli gde broj kompartemta ide do oko 30 za sad. Simulirani su kortikalni piramidalni, spiny-stellate, basket i non-basket neuroni kao i talamicki neuroni (RTN, talamicki interneuroni i talamo-kortikalni "relej" neuroni).
U trenutnim simulacijama je moguce dobiti 5 vrsta ponasanja neurona (Regular Spiking, Low Threshold Spiking, Intrinstically Bursting, Chattering, Fast Spiking) sto je podskup eksperimentalno izmerenih ponasanja neurona u sivoj masi.
Takodje, modelirani su i najvazniji hemijski receptori:
- Glutamatergicki (pobudjujuci): AMPA i NMDA receptori
- GABAergicki (inhibitorni): GABAa i GABAb receptori
Receptorska kinetika (kratkotrajna potencijacija i depresija) je, takodje, implementirana uz pomoc fenomenoloskog modela (Markram et. al.) i modelira kratkotrajnu sinapticku plasticnost koja je u saglasnosti sa eksperimentalnim podacima.
Osim kratkotrajne plasticnosti, modelirana je i dugotrajna sinapticka plasticnost vezana za tajming dolazecih akcionih potencijala (STDP - Spike Timing Dependent Plasticity) koja je, takodje, eksperimentalno potvrdjena i vrlo verovatno predstavlja jednu od glavnih osnova za ucenje u sivoj masi. STDP funkcionise na znacajno duzem intervalu od kratkotrajne sinapticke plasticnosti i, za razliku od nje, menja sinapticke jacine.
Simulator modelira korteks i talamus. Neuroni se alociraju po kortikalnim slojevima (relativne debljine slojeva je moguce menjati) i na osnovu globalne anatomije dobijene vokselizacijom MRI snimka. Neuroni se lokalno (unutar Brodmanovih zona) uvezuju na osnovu statistickih analiza macijeg vizuelnog korteksa (Binzegger et al., 2004) dok se globalna povezanost neurona modelira na osnovu analize difuznih MRI snimka (DSI - Diffusion Spectrum Imaging tehnika) i uparivanjem sa anatomskim modelom radi dobijanja konektoma.
Takodje, implementiran je i OpenGL vizualizator koji mozete videti na slici i videu dole. Vizualizator nije bas super-optimizovan ali ipak koristi VBO (vertex-buffer-objects) tako da je relativno brz na bilo kakvoj diskretnoj grafickoj proizvedenoj u poslednje 3-4 godine... Doduse, za ogromne simulacije preporucujem jaku graficku posto dosta slabih grafickih kartica ima niske limite za velicinu VBO objekata (ako dobijate gresku pri pravljenju simulacije vezanu za VBO - nemate dovoljno memorije na grafickoj za simulaciju), dok ne implementiram volumetricko renderovanje posto se za sada sve renderuje kao prava geometrija ("seljacki" :-).
Za sada je moguce sa F5 videti FFT power spectrum plot tj. koncentraciju aktivnosti u delta/alfa/beta/gama frekventnim regionima kao i odnose sinaptickih jacina tokom vremena (sinapticke jacine se menjaju zbog STDP-a)
Prvi Rezultati
Video dole predstavlja talamokortikalni sistem od 16.7 miliona neurona sa 3.52 milijarde sinapsi. Sama simulacija zauzima oko 350 GB memorije i izvrsava se brzinom od ~0.0005x - ~0x001x realnog vremena na dual Xeon 2687W masini).
Obavezno ukljucite 720p ili 1080p - ako imate 27" ili 30" monitor koji mogu da prikazu 2560 piksela horizontalo, odaberite "original video" u opciji za kvalitet :-)
Prva stvar koja odmah upada u oci je vrlo brza organizacija mreze u nezavisne klastere aktivnosti koji su desinhronizovani na simularnom EEG-u (koji se vidi pri kraju videa)
Ako se mreza ostavi da simulira vise od 15-20 minuta (simulacionog vremena), STDP ce bitno izmeniti ponasanje mreze i "urediti" opaljivanja neurona. Ako bi ste ostavili stalni stimulus i naprasno ga iskljucili posle tog vremena, neko vreme ce ostati "senka" zato sto su se simulirani neuroni "navikli" na konstantnu prisutnost stimulusa bas kao i pravi neuroni....
Evo kako izgleda i radni prozor:
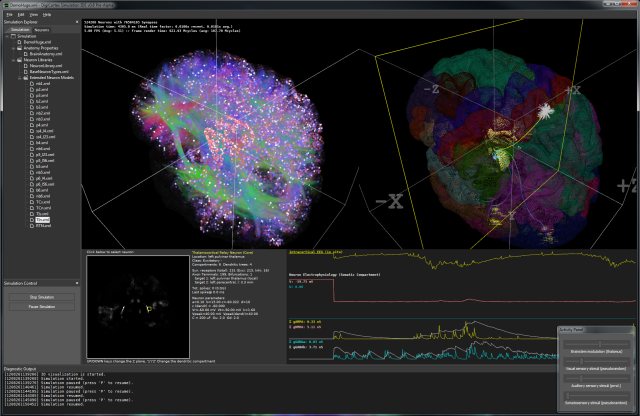
Sledeci koraci
Postoji dosta TODO stvari koje hocu da uradim, i koje zavise od kolicine slobodnog vremena:
- Multi-kompartmentalni neuroni [DONE]
- Slobodna geometrija (sto ce omoguciti simulaciju kortikalnih kolona pa i kompletne sive mase i talamusa) [DONE]
- CUDA/OpenCL procesiranje sto bi trebalo da donese bar 10-20x ubrzanja (nadam se ;-) [DONE]
- Klijent/Server model koji ce omoguciti klaster procesiranje [IN PROGRESS]
- I/O sa bazom podataka sto ce omoguciti snimanje i editovanje mreza
- API za kontrolu i interakciju, i povezivanje sa senzorima
Probajte
Koga zanima - SpikeFun moze skinuti ovde - trenutna verzija je 0.90:
http://www.dimkovic.com/node/1
[Ovu poruku je menjao Ivan Dimkovic dana 25.08.2013. u 17:28 GMT+1]
DigiCortex (ex. SpikeFun) - Cortical Neural Network Simulator:
http://www.digicortex.net/node/1 Videos: http://www.digicortex.net/node/17 Gallery: http://www.digicortex.net/node/25
PowerMonkey - Redyce CPU Power Waste and gain performance! - https://github.com/psyq321/PowerMonkey
http://www.digicortex.net/node/1 Videos: http://www.digicortex.net/node/17 Gallery: http://www.digicortex.net/node/25
PowerMonkey - Redyce CPU Power Waste and gain performance! - https://github.com/psyq321/PowerMonkey
 Re: SpikeFun - Artificial Nervous System Demo
Re: SpikeFun - Artificial Nervous System Demo

